



Photo by Taylor Vick on Unsplash
Using Ansible & Nomad for a homelab (part 1)
How I migrated my Chef homelab to Ansible+Nomad


Part 1 of 2
This article will be split into 2:
- one about the motivation for the migration away from Chef and how I did it using Ansible;
- another one about Nomad, hopefully soon.
What?
I have a small cluster of computers which I have been maintaining over the last 10 years. I've learned an amazing amount of Linux operations thanks to those first Raspberry Pi's but most of all the biggest learning asset I acquired was understanding of the pain of making stuff work manually.
Back then I decided to use Chef as my Config Management (I remember I considered Puppet as well). Don't get me wrong, Ruby is still alive and well (I wouldn't say it's exactly thriving but there are for sure millions of Ruby programmers) - but my engineering career path took me more into direction Java as the main language (with short but interesting excursions into Go and Rust) and Python for everything else.
So, the writings on the wall were there for a long time:
- my Chef cookbooks had to be vendored and manually maintained,
- weird Ruby concoctions had to be used more and more often because I hated maintaining the chef-repo,
- it got harder and harder to match the target Chef version with the available system Ruby version (rvm helped there with unnatural life extension),
- I simply didn't have time to maintain my personal deployment framework BADUC.
It stood for "Bastion/Drone/Usher/Consul" where distributes consul locks were used with node agents and ingress token-driven service triggered deployment. BTW, don't do this. Don't waste time doing something like that, unless you have an abundant amount of free time. It was a major mistake on my side, albeit a nice learning experience. I deleted it all with a laugh on my face - I spent many hours on maintaining it, knowing it will be thrown at some moment in time anyway. Just use off-the-shelf platforms like Nomad or K8s.
I waited for a long time, but finally, I did it: the last remnants of Chef code and setup have been removed and the cluster has moved to Ansible foundation. It took me around 2 months (a couple of hours per week, as much as family life can provide, I guess).
Cluster is hybrid in every sense (unusual for companies but quite a normal thing for home labs):
- part is in the cloud and part on my premises (basement and office);
- there are ARM servers (arm5, aarch64, arm7) and there are the "normal" x64 machines
- some software is set up using Ansible, but mostly I try to target Nomad for new services
- some services are deployed from Github Actions and some from within the network using self-hosted Drone.
The path
Here is my attempt in explaining what I figured out to be the path:
- figure out reasonable Linux OS distribution
- define foundational aspects and deploy them using Ansible
- everything else should work as Nomad job(s).
Linux distribution
There is not a lot of thinking here - if you wish to mix arm servers with x64... you just have to go with Debian (or its derivatives, like Ubuntu).
I know you can set up Ansible to work with any distribution, but for a home lab... it just makes no sense to do it: just expect apt, systemd, and the friends are all there.
This also drastically relaxed Ansible role expectations: my roles are mostly trivial because of this decision.
Foundations
I considered the following things as the most inner ring (or the castle foundations if you like metaphors) of the setup:
- ability to access the SSH port via the default user provided by the distribution using Ansible
- run Ansible roles
- seal the system (no public SSH ever again).
Your cloud provider or your ISP might provide you with direct public IP access which is nice. But it makes no sense for a home lab anymore in 2022 with Cloudflare tunnel, Twingate, Tailscale, etc.
My cloud nodes are currently in the Oracle cloud because of their generous "always free" offering. But, that's just me being a cheap ass.
Standard roles
How to prepare a node for the seal? What are the needed steps to make it happen? For me, the minimum list of the things that must be present on any node in the home lab cluster are:
- add the new system user for Ansible,
- checkout dotfiles from internal Git (this step might fail so it's important to allow for it in case the git server itself is part of the cluster)
- add some "default" packages, (from
ncdutotcpdump, everyone has their favorites here I guess); - change some system files, like
motdmessages just to mark the territory and point out which node you are connected to after SSH login orsshdconfig to block password login and all the other system configurations; - start Tailscale agent and join my tailnet using auto-join feature;
- add promtail to push logs (Loki will be used as the centralized logging service);
- use collectd for metric publishing (InfluxDB will be used for the metrics);
- start Consul agent;
- start Nomad agent.
The actions listed above must be done on all the servers as Ansible roles and only if they are applied can a server be declared as the "homelab cluster member node".
Monitoring
You might ask yourself why would I consider monitoring foundational.
Well, for me as a backend engineer, observability is a paramount concern when building systems. You don't guess what the system is doing, you observe it.
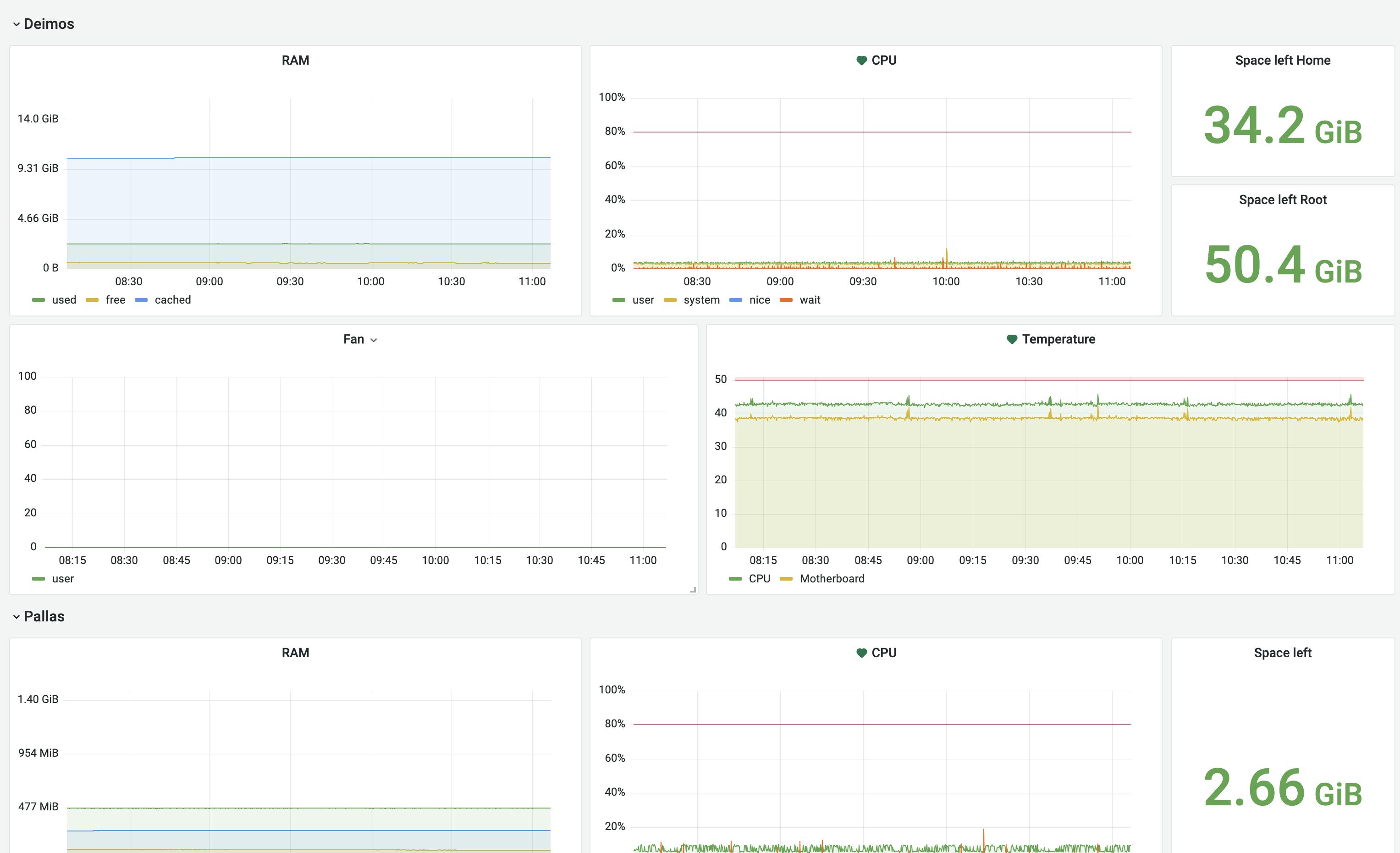
Logging seems like a first thing to look at, for sure, but I find metrics way more interesting for a home lab. You get to see the usage and problems first-hand, like for example situations where a node is over-committed and some swap is needed or when network partitioning shows itself, and so on.
I was focused on lightweight processes and figured out that the smallest footprint comes from Go-driven apps, so I prefer the Grafana stack (Tempo, Loki, Grafana itself), with InfluxDB for metric storage using a 30 days retention period. I'm quite happy and would suggest this stack to everyone.
These Go services are deployed using Nomad, but the agents themselves are for me foundational layer since they should be available and running even when collector services are down. But of course, if you want to throw money at the problem you can avoid collectd/promtail and the monitoring collector services by using their managed offering or just go for Datadog - that's an amazing monitoring suite.
Collectd is something I chose simply because it can be installed on any machine, even my old arm5 Debian. And InfluxDB has support out of the box without any need for additional converters or transformers. Easy on those Raspberry Pi or low-cost cloud node CPUs.
Tailscale
The magic here is Tailscale - after the nodes join the tailnet all of them can talk to each other, regardless of their physical location of NAT or whatever you in front of them.
Nothing comes into the nodes unless it's via the Tailscale network.
If nodes talk to each other, it's via Tailscale.
If there are ingress, publicly open ports, they are quite limited and only on specially marked and isolated nodes. But SSH or other administration ports are never left open for the public.
Thank you Tailscale for such an amazing product!
From the HackerNews geeks I've learned about "Headscale" that is an OSS implementation of the Tailscale server (the only thing which is closed-source in Tailscale setup). I will surely check it out at some point but for now... Tailscale has generous enough free offering that is more than enough for me. For now 😀
Consul/Nomad
I guess you might as why not K8s, right? Well, I know K8s enough, have been using it with one of my previous employers, and am OK with it. But, I wanted something simple for my home lab. Nomad was just a clear winner because of its simplicity, a no-brainer. But, more about how I use it in the next post.
Introducing Nomad demands a Consul cluster up and running, with the agents deployed across the servers.
I knew Consul for a long period and I consider it a nice building block for distributed computing:
- consistent quorum-driven Key/Value storage;
- service discovery;
- Connect service mesh (still not using it, yet).
Non-foundational Ansible services
Some services simply could not be migrated efficiently to Nomad jobs and then they were pushed into a "foundational" setup.
I could choose to force them into Nomad, but I decided to cut my losses here - instead of targeting purity, I decided to have something running and come back later to rethink the approach if the services themselves and/or Nomad further evolve to allow me to fix the problems that blocked me from declaring these workloads as Nomad jobs.
Gitea
This is a popular small-scale self-hosted Git server.
There were too many things that ended up being weird when I tried to put it into a Nomad job:
- creators blocking the idea of the job turning as a
rootuser (even leaving messages in the source code for the smart asses) which is such a pain if you have to useexec/raw_execNomad drivers - git hooks auto-created by gitea hardcode the physical location of the binary (there is an admin action to update the location, but that was just a bit ridiculous and the last drop in the glass full of problems so I just gave up)
PostgreSQL
I prefer running the system packaged version for that platform, although in theory, I should be able to just run a Docker container. PostgreSQL is a database that is suitable for wide number of use cases, from Raspberry Pis to huge RAM-rich sharded cloud clusters.
Public ingress reverse proxy
This will be replaced by an official nomad/Consul gateway envoy proxy at some moment, but for now, I simply had to timebox things in the cluster to non-Connect setup.
I chose Caddy proxy instead of Nginx with which I have more operational experience since it handled HTTPS certificate maintenance without any scripts by me.
To be continued...
In the next installment: some Nomad remarks and personal experiences, including both the good and the bad parts!